
📖 Notes on ISLR
This is a study note on the book An Introduction to Statistical Learning with Applications in R, with my own experimental R-code for each topic. Cheers!

00. Introduction
01. Linear Model
02. Tree-Based Method
03. Unsupervised Learning
04. PCA - A Deeper Dive
05. A Side Note on Hypothesis Test and Confidence Interval
Introduction ↺
Suppose we observe a quantitative response and different predicting variables . We assume that there is a underlying relationship between and :
We want to estimate mainly for two purpose:
prediction: in the case where is not easily obtained, we want to estimate with , and use to predict Y with . Here can be a black box, such as highly non-linear approaches which offers accuracy over interpretability.
inference: in the case where we are more interested in how is affected by the change in each . We need to know the exact form of . For example, linear model is often used which offer interpretable inference but sometimes inaccurate.
Feature
There are important and subtle differences between a feature and a variable.
variable: raw datafeature: data that is transformed, derived from raw data. A feature can be more predictive and have a direct relationship with the target variable, but it isn’t immediately represented by the raw variable.
The need for feature engineering arises from limitations of modeling algorithms:
- the curse of dimensionality (leading to statistical insiginificance)
- the need to represent the signal in a meaningful and interpretable way
- the need to capture complex signals in the data accurately
- computational feasibility when the number of features gets large.
Feature Transformation
The Occam’s Razor principle states that a simpler solutions are more likely to be corret than complex ones.
Consider the following example of modeling a exponentially distributed response. After applying a log transformation, we can view the relation from a different viewpoint provided by the new feature space, in which a simpler model may achieve more predictive power than a complex model in the original input space.1
2
3
4
5
6
7
8
9x1 <- runif(100, 1,10)
x2 <- exp(x1)
df <- data.frame(x1 = x1, x2 = x2)
df$logx2 <- log(df$x2)
ss
options(repr.plot.width=6, repr.plot.height=3)
p1 <- ggplot(data = df, aes(x = x1, y = x2)) + geom_point(size=0.3)
p2 <- ggplot(data = df, aes(x = x1, y = logx2)) + geom_point(size=0.3)
grid.arrange(p1, p2, nrow=1)
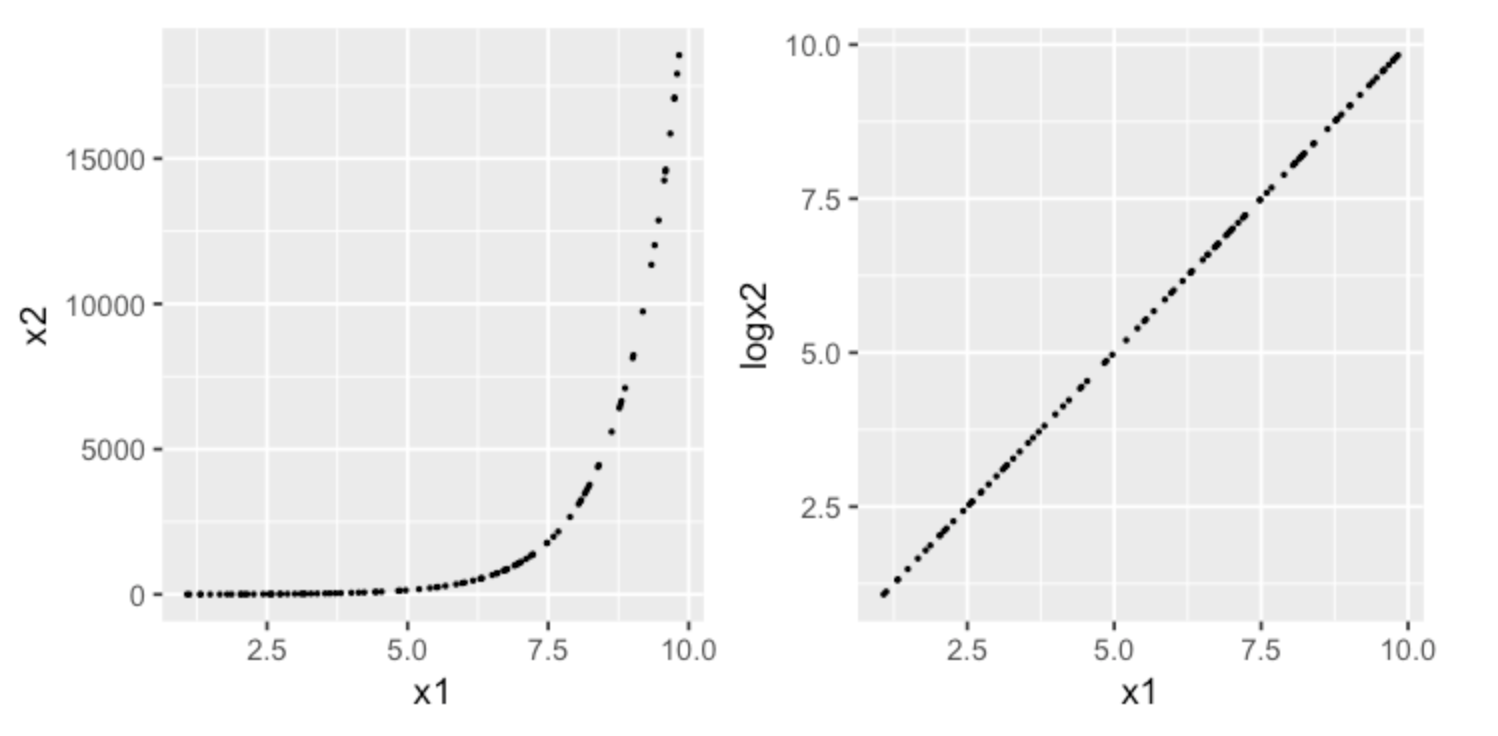
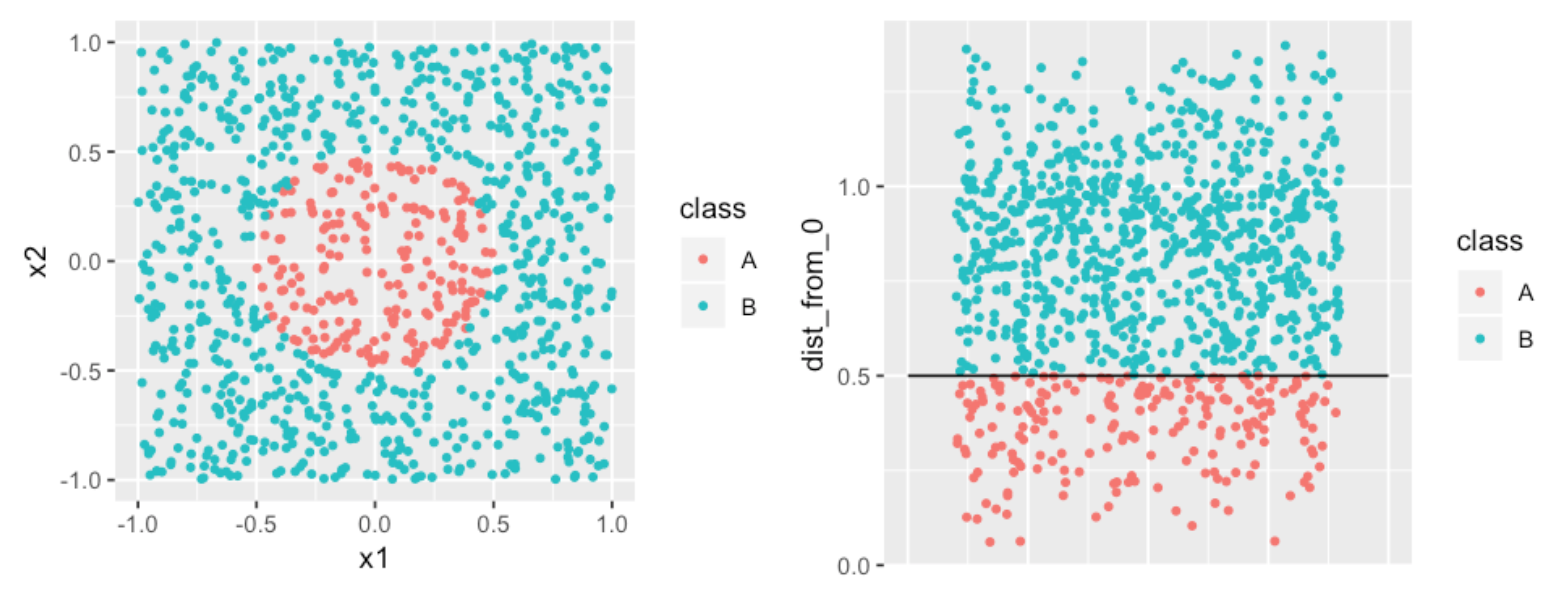
Consider another classification problem, in which we want to identify the boundary between the two classes. A complex model would draw a circle as the divider. A simpler approach would be to create a new feature with distances of each point from the origin. The divider becomes a much simpler straight line.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18x1 <- runif(1000,-1,1)
x2 <- runif(1000,-1,1)
class <- ifelse(sqrt(x1^2 +x2^2) < 0.5, "A", "B")
df <- data.frame(x1 = x1, x2 = x2, class = class)
p1 <- ggplot(data = df, aes(x = x1, y = x2, color = class)) +
geom_point(size=1)
df$dist_from_0 <- sqrt(df$x1^2 + df$x2^2)
p2 <- ggplot(data = df, aes(x = 0, y = dist_from_0, color = class)) +
geom_point(position = "jitter", size=1) +
theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank()) +
annotate("segment", x = -0.5, xend = 0.5, y = 0.5, yend = 0.5)
options(repr.plot.width=8, repr.plot.height=3)
grid.arrange(p1, p2, nrow=1)
Feature Selection
For predictive variables, there are a total of models. We use feature selection to choose a smaller subset of the variable to model.
Forward SelectionWe begin with the null model with no variables and an intercept. We then fit simple linear regression to choose our first variable with the lowest . Same way to choose the next variable to be added until some stoppoing rule.Backward SelectionWe begin with the full model and remove the variable with the largest coefficient -value. Re-fit and remove the next.Mixed SelectionWe begin with the null model and the forward selection technique. Whenever the p-value for a variable exceeds a threshold we remove it.
Regression Problems
In regression problems the variables are quantitative, we use mean squared error, or , to measure the quality of estimator :
A fundamental property of statistical learning that holds regardless of the particular dataset and statistical method is that as model flexibility increases, we can observe a monotone decrease in training MSE and an U-shape in test .
Bias vs Variance
The bias-variance trade off decompose the expected test MSE of a single data point :
where:
variancerefers to the variance of the estimator among different datasets. A highly flexible lead to a high variance, as even small variance in data induce change in the ‘s form.biasrefers to the error due to estimator inflexibility. For example, using linear to estimate non-linear relationship leads to high bias.
Classification Problems
In regression problems the variables are qualitative, we use error rate to measure the quality of estimator :
The Bayes Classifier
The Bayes classifier predict the classification based on the combination of the prior probability and its likelihood given predictor values. With categories , and predictor values , is assigned to category which has the maximum posterior probability:
Where:
The naive Bayes classifier assumes independence between the predictor ‘s, and the formula becomes:
When is continuous, the Guassian naive Bayes classifier assumes that
In R, we use the naiveBayes function from the e1071 package to predict Survival from the Titanic dataset.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20library(e1071)
library(caret)
set.seed(9999)
df=as.data.frame(Titanic)
df <- df[rep.int(seq_len(nrow(df)), df$Freq),]
df$Freq <- NULL
# create a 75/25 train/test split
partition <- createDataPartition(df$Survived, list=FALSE, p=0.75)
train <- df[partition, ]
test <- df[-partition, ]
# fit naive bayes classifier
bayes <- naiveBayes(Survived ~ ., data=train)
# 10-fold validation
bayes.cv <- train(Survived ~ ., data=train,
method = "nb",
trControl = trainControl(method = "cv",
number = 10))
Viewing the model results, the prior probabilities are shown in the “A-priori probabilities” section.1
2
3
4
5
6
7
8
9
10
11> bayes
Naive Bayes Classifier for Discrete Predictors
Call:
naiveBayes.default(x = X, y = Y, laplace = laplace)
A-priori probabilities:
Y
No Yes
0.6767554 0.3232446
The likelihood are shown in the “Conditional probabilities” section1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Conditional probabilities:
Class
Y 1st 2nd 3rd Crew
No 0.09481216 0.10554562 0.34615385 0.45348837
Yes 0.28838951 0.15730337 0.24344569 0.31086142
Sex
Y Male Female
No 0.91323792 0.08676208
Yes 0.53183521 0.46816479
Age
Y Child Adult
No 0.03130590 0.96869410
Yes 0.06928839 0.93071161
The confusionMatrix function from the caret package returns a test Accuracy of 0.7978, which corresponds to an Bayes error rate of 0.2023.
Theoretically, the Bayes classifier produces the lowest error rate if we know the true conditional probability , which is not the case with real data. Therefore, the Bayes classifier serves as an unattainable gold standard against which to compare other methods.1
2
3
4
5
6
7
8
9> confusionMatrix(predict(bayes, test), test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 343 82
Yes 29 95
Accuracy : 0.7978
With 10-fold cross validation, the test error rate is 0.2095.1
2
3
4
5
6
7
8
9> confusionMatrix(predict(bayes.cv, test), test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 332 75
Yes 40 102
Accuracy : 0.7905
K-Nearest Neighbors
The KNN classifier estimate the conditional probability based on the set of K predictors in the training data that are the most similar to , representing by .
Note that the is one minus the -local error rate of a estimate , and therefore with KNN we are picking the that minimizes the -local error rate given .
When , the estimator produces a training error rate of , but the test error rate might be quite high due to overfitting. The method is therefore very flexible with low bias and high variance. As , the estimator becomes more linear.
In R, we use the knn function (with K=1) in the class library to predict Survival from the Titanic dataset.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32library(e1071)
library(class)
set.seed(9999)
df <- as.data.frame(Titanic)
df <- df[rep.int(seq_len(nrow(df)), df$Freq),]
df$Freq <- NULL
# The "knn" function in the "class" library only works with numeric data
df$iClass <- as.integer(df$Class)
df$iSex <- as.integer(df$Sex)
df$iAge <- as.integer(df$Age)
df$iSurvived <- as.integer(df$Survived)
# Create random 75/25 train/test split
train_ind <- sample(seq_len(nrow(df)), size = floor(0.75 * nrow(df)))
df_train <- df[train_ind, c(5:7)]
df_test <- df[-train_ind, c(5:7)]
df_train_cl <- df[train_ind, 4]
df_test_cl <- df[-train_ind, 4]
# Fit KNN
knn <- knn(train = df_train,
test = df_test,
cl = df_train_cl,
k=1)
# 10-fold CV
knn.cv <- tune.knn(x = df[, c(5:7)],
y = df[, 4],
k = 1:20,
tunecontrol=tune.control(sampling = "cross"),
cross=10)
The confusion matrix shows an error rate of 0.1942.1
2
3
4
5
6
7
8
9> confusionMatrix(knn, df_test_cl)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 364 101
Yes 6 80
Accuracy : 0.8058
Now run KNN with the tune wrapper to perform 10-fold cross validation. The result recommends KNN with K=1, which turns out to be the same as what we originally tested.1
2
3
4
5
6
7
8
9
10
11> knn.cv
Parameter tuning of ‘knn.wrapper’:
- sampling method: 10-fold cross validation
- best parameters:
k
1
- best performance: 0.2157576
Summarizing the test error rate for naiveBayes and KNN.1
2naiveBayes (cv10): 0.2095
KNN (cv10, K=1): 0.1942
Linear Model ↺
Simple Linear Regression
A simple linear regression assumes that:
Coefficient Estimate
Given data points , let . We define the residual sum of squares, or , as:
Minimizing as an objective function, we can solve for :
Coefficient Estimate - Gaussian Residual
Furthermore, if we assume the individual error terms are i.i.d Gaussian, i.e.:
We now have a conditional pdf of given :
The maximum log-likelihood estimator for the paramter estimate , , and can be computed as follow:
Setting the partial-derivative of the estimator with respect to each of the parameter to zero, we can obtain the maximum likelihood parameters:
MLE, or maximum likelihood estimation, is a frequentist approach for estimating model parameters based on the assumed underlying model form and error distribution, by maximizing the probability of seeing what we saw in the data. MLE is a near-optimal method of estimation, and is optimal in many cases.
If we assume a Gaussian error distribution and a linear model, then the conclusion above states that maximizing the MLE objective function is the SAME as minimizing the RSS objective function.
More on frequentist vs Bayesian in this SOA work paper. Also see this CMU lecture note and for more detail regarding the derivation.
Model Fit
Recall that we assume there is a underlying relationship between and :
The residual standard error, or , estimates the standard deviation of . Note that RSE is an absolute measure of the lack of fit of the model and depends on units of .
The measures the proportion of variance explained by the regression. is the total sum of squares which measures the total variance in
In a simple regression setting,
Residual Plot
Here is a good article on how to interpret your residual plot.
Summarizing the approaches for different residual issues:
Y-axis Unbalanced: transform targetX-axis Unbalanced: transform predictorHeteroscedasticity: transform target/predictorNon-Linearity: transform predictor; create non-linear modelOutlier: transform target/predictor; remove/assess the outlier;
Multiple Linear Regression
The multiple linear regression takes the form:
F-statistic
We use the F-statistic to test the null hypothesis that there are no relationships between the predictors and target variable.
We calculate the F-statistic as follow:
We expect if is true.
Potential Problems
Non-Linearity Residual plots are useful to detect whether the underlying relationship is non-linear. One of the solutions to this problem is to fit transformations of the predictors such as , , and .
Collinearity This is where two or more predictors are closely correlated with each other, or “collinear”. Collinearity reduces the accuracy of the coefficient estimates by increasing its standard deviation and p-value. One way to detect collinearity is from the correlation matrix or the “pairs” plot in R.
There are two solutions: dropping one of the collinear predictor, or combine the collinear predictors into a single predictor.
Multi-collinearity This is where collinearity exist between three or more predictors when none of the pairwise correlations are high. The best way to assess multi-collinearity if through variance inflation factor, or VIF.
A VIF of indicates no collinearity. A VIF of indicates high collinearity.
Outliers Use residual plot to detect and potentially remove outliers.
Linear Model Selection and Regularization
Linear model can be improved by using alternative fitting procedures, which produce better prediction accuracy and model interpretability.
Subset SelectionSelect a subset of the original predictors and then fit the model.Shrinkage/RegularizationFit the model by shrinking coefficient estimates towards zero, therefore reducing variances of the coefficient estimates.Dimension ReductionProject the predictors onto a M-dimensional subspace, then use the M projections as predictors to fit a linear model with least square.
Subset Selection
The beset subset selection fits a separate least square regression for each combination from the predictors, creating models to compare.
The forward stepwise selection and backward stepwise selection fits a total of models. Specifically, at each step a predictor is added/removed to the model only if it gives the greatest additional improvement (lowest RSS or highest adjusted ) among all the predictors.
After the selection process, we need to determine the optimal model that gives the lowest potential test error, either through:
- Cross-validation, or
Adjusted train error
Example 1: , where is the number of predictors in the subset, and is the variance of error estimated using the full models containing all predictors. Essentially, a penalty term is added to the train RSS to adjust for the fact that the training error tends to underestimate the test error.
Example 2: . The AIC, or Akaike information criterion, uses the maximum likelihood function to assess the relative quality of statistical models give a set of data. In linear models with Gaussian error terms, the maximum likelihood function is equivalent to , and therefore and are proportional to each other.
Example 3:
Example 4: . While always decreases in the stepwise selection as the number of predictors increases, may or may not decrease.
Shrinkage
Ridge Regression
Recall that in least square regression, the coefficient are estimated by minimizing the objective function RSS.
In ridge regression, the objective function include an additional shrinkage penalty, where is a tuning parameter. Note that we do not want to shrink the intercept , which is simply a measure of the mean of the responses:
- As increases, the variance decreases and the bias increases. The model fit usually is improved initially as the variance decreases, but worsen at some point when bias starts to increases rapidly. Cross-validation is often used to select the optimal .
- As , the coefficient approaches .
The ridge regression works when the linear model has low bias and high variance, e.g. when the underlying relationship is close to linear. The ridge regression trades off a small increase in bias for large decrease in variance.
Additionally, it is important to standardize all features when applying regularization. Imagining a feature in dollar and in thousand dollar: the model with the dollar feature will have much higher coefficient compared to the thousand dollar one, leading to larger regularization effect for the dollar feature.
Lasso Regression
Although the ridge regression shrinks the coefficients, it does not eliminiate excess predictors. Model interpretation might be an issue for the ridge regression where the number of predictors are large. The lasso regression overcomes this issue and force some coefficients to be exactly .
However, there are limitations of feature selections using regularization techniques such as lasso, such as model interpretability. In addition, the feature we selected are optimized in linear models, and may not necessarily translate to other model forms.
Note the difference between (ridge) and (lasso) penalty:
- when the coefficients (absolute value) are
greaterthan 1 (when the parameters are large), the penalty is greater than the , andridgeprovides more shrinkage. - when the coefficients (absolute value) are
smallerthan 1 (when the parameters are small), the penalty is greater than the , andlassoprovides more shrinkage.
In R, we use the glmnet package to compute ridge and lasso regressions to predict mpg from the mtcars built-in data set.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41library(glmnet)
library(caret)
set.seed(9999)
# data
df <- as.data.frame(mtcars)
x <- model.matrix(mpg~., df)[, -1]
y <- df$mpg
# 75/25 train/test split
partition <- createDataPartition(df$mpg, list = FALSE, p = .75)
df_train <- df[partition, ]
df_test <- df[-partition, ]
x_train <- x[partition, ]
x_test <- x[-partition, ]
y_train <- y[partition]
y_test <- y[-partition]
# fit regression
m1 <- lm(mpg ~ ., df_train)
m1.pred <- predict(m1, df_test)
m1.mse <- round(mean((y_test - m1.pred)^2), 2)
# fit ridge regression
m2 <- cv.glmnet(x_train, y_train, alpha=0, nfolds=6)
m2.bestlambda <- m2$lambda.min
m2.pred <- predict(m2, s=m2.bestlambda, x_test)
m2.mse <- round(mean((y_test - m2.pred)^2), 2)
# fit lasso regression
m3 <- cv.glmnet(x_train, y_train, alpha=1, nfolds=6)
m3.bestlambda <- m3$lambda.min
m3.pred <- predict(m3, s=m3.bestlambda, x_test)
m3.mse <- round(mean((y_test - m3.pred)^2), 2)
# get coefficients
m2.best <- glmnet(x_train, y_train, alpha=0, lambda=m2.bestlambda)
m3.best <- glmnet(x_train, y_train, alpha=1, lambda=m3.bestlambda)
comp <- cbind(coef(m1), coef(m2.best), coef(m3.best))
colnames(comp) <- c("original", "ridge", "lasso")
The test MSE are as follow. Note that both ridge and lasso regression perform better than the original regression.1
2
3
4
5
6> m1.mse
[1] 16.64
> m2.mse
[1] 3.66
> m3.mse
[1] 6.61
We also made a comparison of the coefficients, based on the normal regression and the regularized regression with cv-optimal .1
2
3
4
5
6
7
8
9
10
11
12
13
14> comp
11 x 3 sparse Matrix of class "dgCMatrix"
original ridge lasso
(Intercept) -19.52071389 19.420775180 14.002192375
cyl 1.69431225 -0.275408324 .
disp 0.01185998 -0.004705579 .
hp -0.01449594 -0.011129305 -0.002545135
drat 3.08676192 1.272808791 1.334526777
wt -3.19280650 -1.137507747 -2.254408320
qsec 1.02473436 0.117671597 0.331182874
vs 0.97127211 0.677494227 .
am 2.63740010 1.633418877 1.703501439
gear 3.36943552 0.794847062 1.571031414
carb -1.45443855 -0.588427657 -1.162118484
Resampling Method
Resampling methods involve repeatedly drawing samples from a training set to re-fit the model.
Cross-Validation
We often use the test error rate to determine and compare how well a statistical learning model perform. However, in the absence of a large designated test set, the test error rate can be difficult to estimate. The train error rate is often quite different from the test error rate. Therefore, cross-validation can be used to estimate the test error rates by creating validation sets off the train data.
A k-fold cross validation involves randomly dividing the observations into -groups. The process is repeated -times where each group is treated as a validation set while fitting the remaining groups. The -fold CV test MSE is the average of all the MSE from each validation set:
The leave-one-out cross validation, or LOOCV, is a special case of -fold CV with . Since LOOCV requires fitting the model times, with being equal to number of train data points. The -fold CV with are more feasible computationally as it only needs to fit the model times.
Bootstrap
Bootstrap provides a measure of accruacy of either a parameter estimate or a given statistical learning method. It can be used to estimate variance of a parameter by repeatedly re-sampling the same data set with replacement (i.e. duplicate data entries allowed) while re-calculating the parameter based on each re-sample.
Hyper-Parameter Tuning
We specify numerious constants called hyperparameter during our modeling process, e.g. , , etc. To set these constant such that our model can predict accruately while avoiding over-complexity and overfitting, we tune our hyperparameter with cross validation. For more details see the auto claim notebook.
Generalized Linear Model
Generalized linear models were developed by Nelder and Wedderburn in a paper published in 1972 to provide a flexible framework which introduces a link function that transform the linear combinations of predictors.
An Ordinary Linear Model has many limitations:
- As ordinary linear model produces a numeric response, it requires the assumptions of orderings to predict qualitative responses.
- Negative values may be predicted when not allowed.
- When the variance of the target variable depends on the mean, the homoscedasticity assumption is violated, and therefore the least square estimator is no longer the MLE estimator and various statistical test would not hold.
- Sensitive to outliers.
- Does not perform well with non-linear relationships.
The Generalized Linear Models relaxes the assumptions of OLM. First, GLM relaxes the normal residual assumption of OLM, and allow the target variable to follow any distribution within the exponential distribution family:
With regard to this distribution, there exists a canonical link function associated with it that simplifies the mathematics of solving GLM analytically.
- Normal => Identity:
- Exponential/Gamma => Negative Inverse:
- Inverse Gaussian => Inverse Square:
- Poisson => Log:
- Bernoulli/Binomial/Multinomial => Logit:
We can either choose the canonical link function or pick another one (which may not lead to a converged GLM solution, however). With this link function, GLM assumes that the expectation of the target is the inverse linked linear combination of predictors:
With all above assumptions satisfy, the coefficient of a GLM model can then be solved:
Logistic Regression
The logistic regression model is popular for classification problems. With two response classes, we can calculate the probability of assigning the response in each class and predict the response by choosing the class with the higher probability. or more than two response classes, multiple-class logistic regression is available but the discrimentant analysis is more popular.
We define as our new response variable and the link function: logit function, short for logistic function, as such:
Since we assume a linear relationship between our predictor and the linked reponse , we have:
Therefore,
Now we have a nice property of , which is exactly what we wanted to model probability responses. The quantity is called the odds.
In R, we use the glm function (with family=binomial) in the predict Survival from the Titanic dataset.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37library(e1071)
library(caret)
set.seed(9999)
df <- as.data.frame(Titanic)
df <- df[rep.int(seq_len(nrow(df)), df$Freq), ]
df <- subset(df, select = -c(Freq))
# Binarize class, sex and age
df.new <- predict(dummyVars("~Class+Sex+Age",
df,
sep="_",
fullRank=TRUE), df)
df.new <- as.data.frame(df.new)
df.new["Survived"] <- df$Survived
df <- df.new
# Create random 80/20 train/test split
train_ind <- sample(seq_len(nrow(df)), size = floor(0.80 * nrow(df)))
df_train <- df[train_ind, ]
df_test <- df[-train_ind, ]
# Fit Logistic Regression
model <- glm(Survived~.,
df_train,
family=binomial)
summary(model)
contrasts(df$Survived)
# Predict In-Sample
prob_train <- predict(model, df_train, type="response")
pred_train <- rep("No", nrow(df_train))
pred_train[prob_train > .5] <- "Yes"
# Predict Out-Of-Sample
prob_test <- predict(model, df_test, type="response")
pred_test <- rep("No", nrow(df_test))
pred_test[prob_test > .5] <- "Yes"
From summary(model), note that most coeefficients are significant.1
2
3
4
5
6
7
8
9> summary(model)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.3094 0.3132 0.988 0.323
Class_2nd -1.1163 0.2187 -5.105 3.31e-07 `
Class_3rd -1.7041 0.1918 -8.883 < 2e-16 `
Class_Crew -0.8848 0.1773 -4.991 6.01e-07 `
Sex_Female 2.3691 0.1555 15.235 < 2e-16 `
Age_Adult -0.6289 0.2767 -2.273 0.023 *
Note that probability of 1 correspond to “Yes” in the Survived variable.1
2
3
4> contrasts(df$Survived)
Yes
No 0
Yes 1
From in-sample confusion matrix.1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(pred_train), df_train$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 1087 296
Yes 102 275
Accuracy : 0.7739
From out-of-sample confusion matrix.1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(pred_test), df_test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 277 66
Yes 24 74
Accuracy : 0.7959
Comparing the test error rate between naiveBayes, KNN and logistic regression.1
2
3naiveBayes (cv10): 0.2095
KNN (cv10, K=1): 0.1942
logistic regression: 0.2041
Poisson Regression
The Poisson distribution expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant rate and independently of the time since the last event.
We can fit Posisson regression if we observe that the frequencies of response variable exhibits a Poisson shape. We will create a new response vector and assumes that has an underlying linear relationship in .
That is, we assume that for each , . The log link function ensures that is strictly positive.
Note that we had made a strong assumption that for each , the mean and variance of are the same, as dictated by the Poisson distribution. However, if the data shows larger variance than expected, or overdispersion, we can then use the quasi-Poisson regression, which is essenstially the negative binomial distribution with looser assumptions than Poisson.
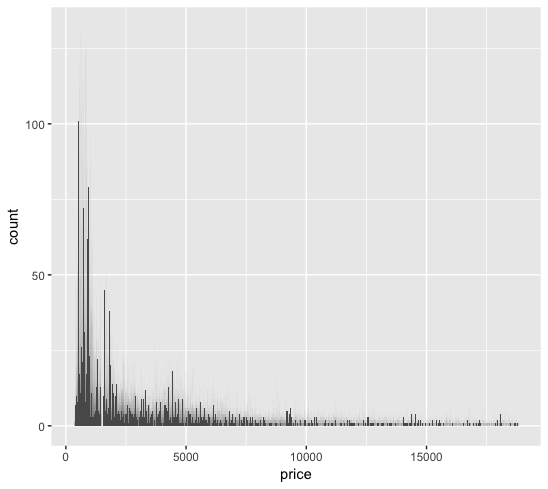
In the diamonds dataset from the ggplot2 package, we plotted the histogram of the price data from 50,000 observations.
1 | library(ggplot2) |
The price data shows resemblence to a Poisson distribution.
We fitted four different models: linear, ridge, lasso, and Poisson regressions.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62library(e1071)
library(ggplot2)
library(caret)
library(glmnet)
set.seed(9999)
df <- as.data.frame(diamonds)
# caret::dummyVars does not work well with ordered factor. change to unordered.
df["cut_1"] <- factor(df$cut, order=FALSE)
df["color_1"] <- factor(df$color, order=FALSE)
df["clarity_1"] <- factor(df$clarity, order=FALSE)
# Binarize Category Variable
dummy <- dummyVars(~ cut_1 + color_1 + clarity_1, df, sep="_", fullRank=TRUE)
df.new <- as.data.frame(predict(dummy, newdata = df))
df.new["carat"] <- df$carat
df.new["price"] <- df$price
df <- df.new
x <- model.matrix(price~., df)[, -1]
y <- df$price
# Create random 80/20 train/test split
partition <- sample(seq_len(nrow(df)), size = floor(0.80 * nrow(df)))
df_train <- df[partition, ]
df_test <- df[-partition, ]
x_train <- x[partition, ]
x_test <- x[-partition, ]
y_train <- y[partition]
y_test <- y[-partition]
# Fit Linear Regression
m1 <- lm(price~., df_train)
m1.pred <- predict(m1, df_test)
m1.mse <- round(mean((y_test - m1.pred)^2), 2)
# Fit Ridge Regression
m2 <- cv.glmnet(x_train, y_train, alpha=0, nfolds=10)
m2.bestlambda <- m2$lambda.min
m2.pred <- predict(m2, s=m2.bestlambda, x_test)
m2.mse <- round(mean((y_test - m2.pred)^2), 2)
# Fit Lasso Regression
m3 <- cv.glmnet(x_train, y_train, alpha=1, nfolds=10)
m3.bestlambda <- m3$lambda.min
m3.pred <- predict(m3, s=m3.bestlambda, x_test)
m3.mse <- round(mean((y_test - m3.pred)^2), 2)
# Fit Poisson Regression
m4 <- glm(price~., df_train, family=poisson(link="log"))
m4.pred <- predict(m4, df_test)
m4.mse <- round(mean((y_test - exp(m4.pred))^2), 2)
# Fit quasiPoisson Regression
m5 <- glm(price~., df_train, family=quasipoisson(link="log"))
m5.pred <- predict(m5, df_test)
m5.mse <- round(mean((y_test - exp(m5.pred))^2), 2)
# Compare Coefficient
m2.best <- glmnet(x_train, y_train, alpha=0, lambda=m2.bestlambda)
m3.best <- glmnet(x_train, y_train, alpha=1, lambda=m3.bestlambda)
comp <- cbind(coef(m1), coef(m2.best), coef(m3.best), coef(m4), coef(m5))
colnames(comp) <- c("original", "ridge", "lasso", "Poisson", "quasiPoi")
Showing the results. We can see that lasso regression improved upon ridge. However, the Poisson regression show very high MSE, and not improved by using quasi-Poisson to deal with overdispersion.1
2
3
4
5
6
7
8
9
10
11
12
13
14> m1.mse
[1] 1296082
> m2.mse
[1] 1662769
> m3.mse
[1] 1296773
> m4.mse
[1] 5237564
> m5.mse
[1] 5237564
Comparing coefficients:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22> comp
19 x 5 sparse Matrix of class "dgCMatrix"
original ridge lasso Poisson quasiPoi
(Intercept) -7369.2859 -2751.693983 -7083.4777 5.17185599 5.17185599
cut_1_Good 686.6877 112.163397 657.1100 0.17515789 0.17515789
`cut_1_Very Good` 864.3160 319.828814 838.9901 0.20528993 0.20528993
cut_1_Premium 893.6342 367.364011 866.6581 0.18009057 0.18009057
cut_1_Ideal 1025.5579 421.231162 999.8031 0.20406528 0.20406528
color_1_E -225.3985 -23.486004 -205.5637 -0.05660526 -0.05660526
color_1_F -294.1807 2.717515 -274.2126 -0.03079075 -0.03079075
color_1_G -522.9599 -112.556133 -501.1661 -0.10597258 -0.10597258
color_1_H -997.6266 -490.885083 -975.9837 -0.25411004 -0.25411004
color_1_I -1452.1455 -749.323400 -1426.9279 -0.42200863 -0.42200863
color_1_J -2343.2864 -1450.247841 -2315.1429 -0.63819087 -0.63819087
clarity_1_SI2 2612.5463 -472.362109 2345.9392 1.14176901 1.14176901
clarity_1_SI1 3555.6013 149.192295 3287.0687 1.38540593 1.38540593
clarity_1_VS2 4210.3193 671.522828 3940.7103 1.50843614 1.50843614
clarity_1_VS1 4507.7144 861.334888 4235.9431 1.58850692 1.58850692
clarity_1_VVS2 4965.2210 1192.175019 4691.8855 1.66443836 1.66443836
clarity_1_VVS1 5072.6388 1162.725817 4796.5710 1.61060572 1.61060572
clarity_1_IF 5436.6567 1476.377453 5158.0224 1.72336616 1.72336616
carat 8899.8818 7672.223943 8883.8976 1.65798106 1.65798106
We are curious as to why the Poisson regression perform much worse than a simple linear regression, when the reponse variable clearly shows Poisson patterns.
1 | p1 <- ggplot() + |
We first look at the linear regression fit, where the black dots are the original data and the red dots are the fitted data:
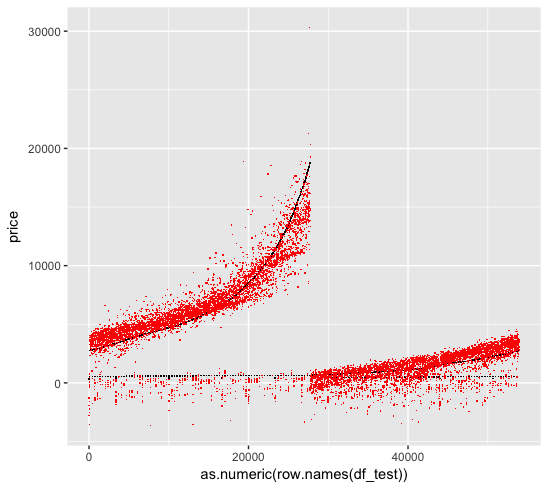
We then look at the Poisson regression fit. Unfortunately the Poisson regression create ultra-high predictions for some values, which skew the MSE matrix. This is we forget to log the numerical variable (carat) when we use log link function, which results in a exponential shape for the prediction.
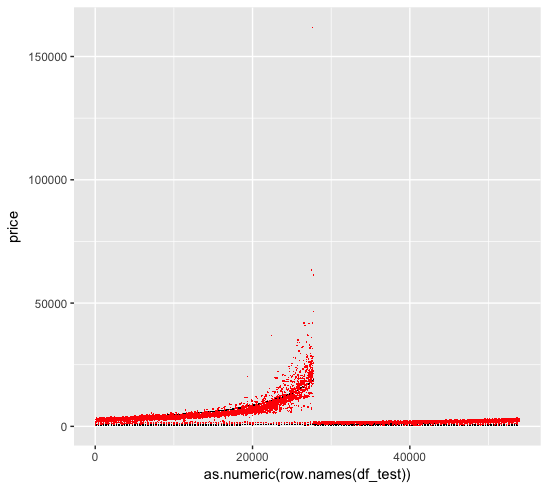
We change the code as follow:1
2
3
4
5
6
7
8
9# Fit Poisson Regression
m4 <- glm(price~-carat+log(carat), df_train, family=poisson(link="log"))
m4.pred <- predict(m4, df_test)
m4.mse <- round(mean((y_test - exp(m4.pred))^2), 2)
# Fit quasiPoisson Regression
m5 <- glm(price~-carat+log(carat)., df_train, family=quasipoisson(link="log"))
m5.pred <- predict(m5, df_test)
m5.mse <- round(mean((y_test - exp(m5.pred))^2), 2)
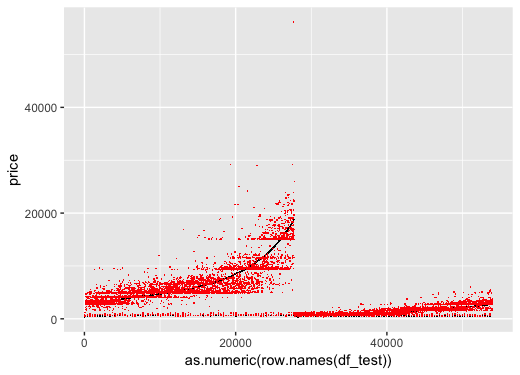
The mse are now better:1
2
3
4> m4.mse
[1] 2544181
> m5.mse
[1] 2544181
Plotting the prediction. We can see that other than one prediction outlier, the overall predictions are better than when we did not log the carat.
Goodness of Fit
Deviance is a measure of the goodness of fit of a generalized linear model, similar to a in the simple linear model. . The default value is called null deviance and is the deviance calculated when the response variable is predicted using its sample mean.
Adding additional feature to the model would generally decrease the deviance and decrease the degree of freedoms.
Tree-Based Method ↺
The tree-based method involve segmenting the predictor space into several regions to make a prediction for a given observation. There are several advantages to the tree-based methods:
- Easy to explain
- Intuitive to human reasoning
- Graphic and interpretable
- No need to dummy variables for qualitative data
On the other hand, disadvantages:
- Lower predictive accuracy
- Sensitive to change in data
Several techniques can make significant improvement to compensate the disadvantages, namely bagging, random forest and boosting.
Regression Tree
In a linear regression model, the underlying relationship is assumed to be:
Whereas in a regression tree model, the underlying is assumed to be:
Where each represent a partition of the feature space. The goal is to solve for the partition set which minimize the objective function:
To find efficiently, we introduce recursive binary splitting, which is a top-down and greedy approach. It is greedy because it is short-sighted in that it always chooses the current best split, instead of the optimal split overall.
Due to the greedy nature, it is preferred that we first grow a complex tree and then prune it back, so that all potential large reductions in RSS are captured.
Cost Complexity Pruning
The cost complexity pruning approach aim to minimize the objective function, give each value of :
Where is the number of terminal nodes of subtree where is the original un-prune tree. The tuning parameter controls the complexity of the subtree , penalizing any increase in nodes. The goal is to prune the tree with various and then use cross-validation to select the best .
This is similar to the lasso equation, which also introduce a tuning parameter to control the complexity of a linear model.
In R, we use the rpart library, which stands for recursive partitioning and regression trees, to fit a regression tree to predict mpg in our mtcars dataset.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15library(caret)
library(rpart)
library(rpart.plot)
set.seed(9999)
df <- as.data.frame(mtcars)
# create a 75/25 train/test split
partition <- createDataPartition(df$mpg, list=FALSE, p=0.75)
train <- df[partition, ]
test <- df[-partition, ]
# fit regression tree
t1 <- rpart(mpg ~ ., train)
t1.predict <- predict(t1, test)
t1.mse <- round(mean((test$mpg - t1.predict)^2), 2)
The test MSE, as compared to the previous linear models.1
2
3
4
5
6
7
8
9
10
11# regression tree
> t1.mse
[1] 11.59
# linear regression
> m1.mse
[1] 16.64
> m2.mse
[1] 3.66
> m3.mse
[1] 6.61
Plotting the tree with rpart.plot(t1) command.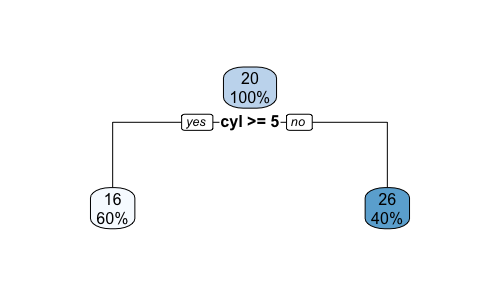
Classification Tree
Classification tree is very similar to regression trees expect we need an alternative method to RSS when deciding a split. There are three common approaches.
Classification error rate:
Where represents the porportion of train observations from the -th parent node that are from the -th child node. However, the this approach is not sufficiently sensitive to node impurity for tree-growing, compared to the next two.
Gini index:
Note that the Gini index decreases as all get closer to or . Therefore it is a measure of the node purity.
Entropy:
The Entropy is also a measure of the node purity and similar to the Gini index numerically.
For a two-class decision tree, the impurity measures calculated from different methods for a given are simulated below with python.
1 | import matplotlib.pyplot as plt |
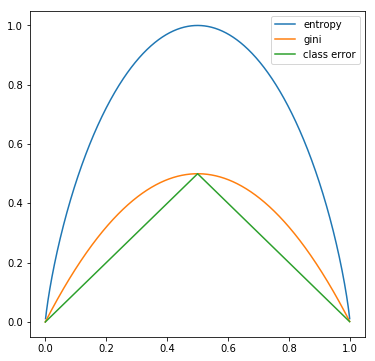
We can see that all three method are similar and consistent with each other. Entropy and the Gini are more sensitive to changes in the node probabilities, therefore preferrable when growing the trees. The classification error is more often used during complexity pruning.
Information Gain
When the measure of node purity is calculated, we want to maximize the information gain after each split. We use and to denote the parent and child node, with entropy as the measure. is the number of observations under the parent node:
In R, we use the rpart library to create a classification tree to predict Survived in the Titanic data set.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22library(caret)
library(rpart)
library(rpart.plot)
set.seed(9999)
df <- as.data.frame(Titanic)
df <- df[rep.int(seq_len(nrow(df)), df$Freq), ]
df <- subset(df, select = -c(Freq))
# create a 75/25 train/test split
partition <- createDataPartition(df$Survived, list=FALSE, p=0.75)
train <- df[partition, ]
test <- df[-partition, ]
# fit classification tree
t2 <- rpart(Survived ~ ., train)
t2.prob <- predict(t2, test)
t2.pred <- rep("No", nrow(t2.prob))
t2.pred[t2.prob[, 2] > .5] <- "Yes"
# pruning
t2.prune <- prune(t2, cp = 0.05)
rpart.plot(t2.prune)
The confusion matrix shows:1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(t2.pred), test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 368 105
Yes 4 72
Accuracy : 0.8015
Plotting the tree with rpart.plot(t2).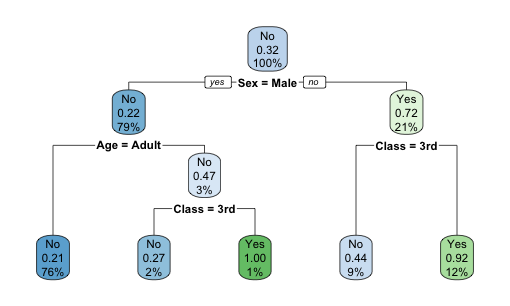
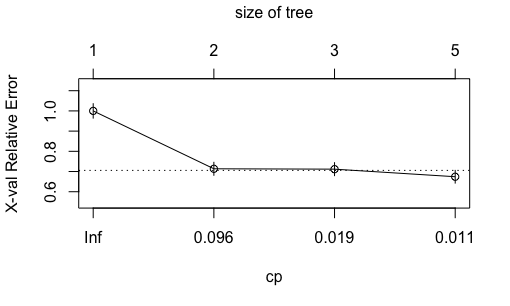
Plotting the complexity parameter against the cross-validation relative error with plotcp(t2). Although the relative error is at the lowest at nodes, comparable level of relative error was achieved at nodes. Because decision tree is prone to overfitting, here we manually prune the tree back to 2 nodes.
Plotting the tree with rpart.plot(t2.prune).
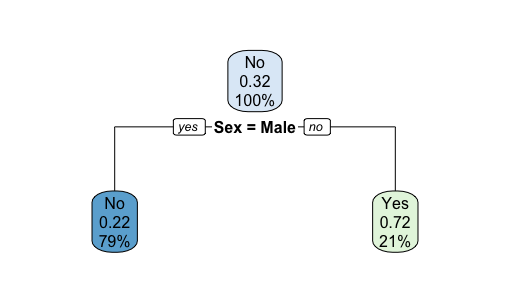
The confusion matrix after pruning. We lose a small bit of out-of-sample accuracy due to manual pruning.1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(t2.prune.pred), test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 343 83
Yes 29 94
Accuracy : 0.796
Comparing the test error rate with naiveBayes, KNN and logistic regression.1
2
3
4naiveBayes (cv10): 0.2095
KNN (cv10, K=1): 0.1942
classification tree: 0.1985
classification tree (prune): 0.2040
Confusion Matrix
The confusion matrix is a convenient summary of the model prediction. In our previous example with the un-pruned tree:
1 | > confusionMatrix(as.factor(t2.pred), test$Survived) |
There are four types of prediction:
- True Positive (TP): 72
- True Negative (TN): 368
- False Positive (FP), or Type I Error: 4
- False Negative (FN), or Type II Error: 105
Several metrics can be computed:
- Accuracy: (TP + TN) / N = (72 + 368) / 549 = 0.8015
- Error Rate: (FP + FN) / N = 1 - Accuracy = 0.1985
- Precision: TP / (Predicted Positive) = 72 / (72 + 4) = 0.9474
- Sensitivity: TP / (Actually Positive) = 72 / (72 + 105) = 0.4068
Receiver Operator Characteristic Curve
The ROC curve can be used to evaluate the performacne of our model. The ROC curve plots the TPR (true positive rate) against FPR (false positive rate) over a range of cutoff values:
- TPR = TP / (Actually Positive) = 0.4068
- FPR = FP / (Actually Negative) = 0.0107
In python, we can create a ROC curve from our previous prediction TPR and FPR:1
2
3
4
5
6
7
8
9
10
11
12
13
14import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0, 1, 0.0001)
plt.plot(x, x)
plt.xlabel('FPR')
plt.ylabel('TPR')
x2=0.0107
y2=0.4680
plt.scatter(x2, y2, s=20, color='red')
plt.plot([0, x2], [0, y2], 'r-', color='red')
plt.plot([x2, 1], [y2, 1], 'r-', color='red')
plt.title('ROC Plot')
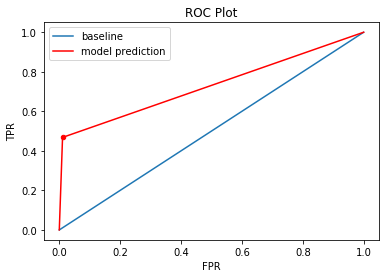
The baseline line refers to a model/cutoff where all observations in the testing set are predicted to be positive (point x=1, y=1), or negative (point x=0, y=0). The area under the red lines and above the x-axis is an estimate of the model fit and is called AUC, or area under the ROC curve.
An AUC of 1 means that the model has a TPR of 1 and FPR of 0.
Ensemble Methods
Bagging
The decision tree method in general suffer from high model variance, compared to linear regression which shows low variance. Bootstrap aggregation, or bagging is a general-purpose procedure for reducing variance of a statistical model without affecting the bias. It is particular useful in the decision tree model context.
For regression trees, construct regression trees using bootstrapped (repeatedly sampled) training sets. These trees grow deep and are not pruned, therefore having high variance. At the end, average the trees to reduce the variance.
For classification trees, construct classification trees. When predicting a test observation, take the majority classification resulted from the trees.
Note that the bagging results are more accruate but less visual. We can obtain the variable importances by computing the total RSS/Gini decreases by splits over each predictors, hence providing better interpretations of the results.
Random Forest
Random forest improves upon bagged trees by de-correlating the trees. At each split, only predictors are considered, isolating effects on single feature with large influences.
In R, use the randomForest package:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18library(caret)
library(randomForest)
set.seed(9999)
df <- as.data.frame(Titanic)
df <- df[rep.int(seq_len(nrow(df)), df$Freq), ]
df <- subset(df, select = -c(Freq))
# create a 75/25 train/test split
partition <- createDataPartition(df$Survived, list=FALSE, p=0.75)
train <- df[partition, ]
test <- df[-partition, ]
# fit random forest
rf <- randomForest(formula = Survived ~ .,
data = train,
ntree = 100,
importance = TRUE)
In-sample confusion matrix:1
2
3
4
5
6
7
8
9
10
11
12
13> rf
Call:
randomForest(formula = Survived ~ ., data = train, ntree = 100, importance = TRUE)
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 1
OOB estimate of error rate: 23.43%
Confusion matrix:
No Yes class.error
No 1063 55 0.04919499
Yes 332 202 0.62172285
Out-of-sample confusino matrix:1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(predict(rf, test)), test$Survived)
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 368 108
Yes 4 69
Accuracy : 0.796
Comparing the test error rate with naiveBayes, KNN and logistic regression.1
2
3
4
5naiveBayes (cv10): 0.2095
KNN (cv10, K=1): 0.1942
classification tree: 0.1985
classification tree (prune): 0.2040
random forest: 0.2040
Boosting
Boosting is also a general-purpose procedure for improving accuracy of the statistical model. In boosting, we repeatedly fit new trees to the residuals from the previous tree, and add the new trees to the main tree such that a loss function is minimized (subject to shrinkage parameter , typical 0.01, to control overfitting). CV is often used to determine the total number of trees to be fitted.
A gradient boosting machine is an algorithm that calculates the gradient of the loss function and update the paramters such that the model moves in the direction of the negative gradient, thus closer to a minimum point of the loss function.
XGBoostis an open-source software library that provides agradient boostingframework for R. XGBoost initially started as a research project by Tianqi Chen as part of the Distributed (Deep) Machine Learning Community (DMLC) group
1 | llibrary(caret) |
Feature importance:1
2
3
4> xgb.importance(feature_names = dimnames(train.dm)[[2]], model = model)
Feature Gain Cover Frequency
1: Class3rd 0.8347889 0.5957944 0.5
2: Class2nd 0.1652111 0.4042056 0.5
AUC result:1
2> auc(test$Survived_Ind, xgb.prob)
Area under the curve: 0.6033
Confusion matrix:1
2
3
4
5
6
7
8
9> confusionMatrix(as.factor(xgb.pred), as.factor(test_2$Survived))
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 370 180
Yes 0 0
Accuracy : 0.6727
Unfortunately xgboost predict everything to be “No”
Comparing the test error rate with naiveBayes, KNN and logistic regression.1
2
3
4
5
6naiveBayes (cv10): 0.2095
KNN (cv10, K=1): 0.1942
classification tree: 0.1985
classification tree (prune): 0.2040
random forest: 0.2040
xgboost: 0.3273
Ensemble Model Interpretation
Feature Importance ranks the contribution of each feature.Partial Dependence Plots visualizes the model’s average dependence on a specific feature (or a pair of features).
Unsupervised Learning ↺
In supervised learning, we are provided a set of observations , each containing features, and a response variable . We are interested at predicting using the observations and features.
In unsupervised learning, we are interested at exploring hidden relationships within the data themself without involving any response variables. It is “unsupervised” in the sense that the learning outcome is subjective, unlike supervised learning in which specific metrics such as error rates are used to evaluate learning outcomes.
PCA
See the PCA section below.
K-Mean Clustering
Clustering seek to partition data into homogeneous subgroups. The K-Mean clustering partitions data into distinct and non-overlapping clusters , by minimizing the objective function of total in-cluster variation , which is the sum of all pair-wise squared Euclidean distances between the observations in the cluster, divided by the number of observations in the cluster.
Algorithm
The algorithm divides data into initial cluster, and reassign observations to the cluster with the closest cluster centroid (mean of all previous observations in the cluster).
The K-Mean clustering algorithm finds a local optimum, and therefore depend on the initial cluster. So it is important to repeat the process with different initial points, and then select the best result based on minimum total in-cluster variation.
- The
nstartparameter in thekmeanfunction in R specifies the number of random starting centers to try and the one ended with the optimal objective function value will be selected.
It is also important to check for outliers, as the algorithm would let the outlier become its own cluster and stops improving.
Standardization
It is a must to standardize the variables before performing k-mean cluster analysis, as the objective function (Euclidean distance, etc.) is calculated from the actual value of the variable.
Curse of Dimensionality
The curse of dimensionality describe the problems when performing clustering on three or more dimensional space, where:
- visualization becomes harder
- as the number of dimensions increases, the Euclidean distance between data points are the same on average.
The solution is to reduce the dimensionality before using clustering technique.
The Elbow Method
Each cluster replaces its data with its center. In other words, with a clustering model we try to predict which cluster a data point belongs to.
A good model would explain more variance in the data with its cluster assignments. The elbow method looks at the statistics defined as:
As soon as the additional F statistics drops/stops increasing when adding a new cluster, we use that number of clusters.
Hierarchical Clustering
The hierarchical clustering provide flexibilities in terms of the number of clusters . It results in a tree-based representation of the data called dendrogram, which is built either bottom-up/agglomerative or top-down/divisive.
Hierarchical clustering assumes that there exists a hierarchical structure. In most feature generation cases, we prefer k-means clustering instead.
Agglomerative
An agglomerative hierarchical cluster starts off by assigning each data point in its own cluster. Each step in the clustering process two similar clusters with minimum distance among all are merged, where the distance is calculated between the elements within the cluster that are closest (single-linkage) or furthest (complete-linkage)
PCA - A Deeper Dive ↺
PCA finds low dimensional representation of a dataset that contains as much as possible of the variation. As each of the observations lives on a -dimensional space, and not all dimensions are equally interesting.
Linear Algebra Review
Let be a matrix. With , the determinant of can be calculated as follow.
Properties of determinant:
A real number is an eigenvalue of if there exists a non-zero vector (eigenvector) in such that:
The determinant of matrix is called the characteristic polynomial of . The equation is called the characteristic equation of , where the eigenvalues are the real roots of the equation. It can be shown that:
Matrix is invertible if there exists a matrix such that . A square matrix is invertible if and only if its determinant is non-zero. A non-square matrix do not have an inverse.
Matrix is called diagonalizable if and only if it has linearly independent eigenvectors. Let denote the eigen vectors of A and denote the diagonal vector. Then:
If matrix is symmetric, then:
- all eigenvalues of are real numbers
- all eigenvectors of from distinct eigenvalues are orthogonal
Matrix is positive semi-definite if and only if any of the following:
- for any matrix ,
- all eigenvalues of are non-negative
- all the upper left submatrices have non-negative determinants.
Matrix is positive definite if and only if any of the following:
- for any matrix ,
- all eigenvalues of are positive
- all the upper left submatrices have positive determinants.
All covariance, correlation matrices must be symmetric and positive semi-definite. If there is no perfect linear dependence between random variables, then it must be positive definite.
Let be an invertible matrix, the LU decomposition breaks down as the product of a lower triangle matrix and upper triangle matrix . Some applications are:
- solve :
- solve :
Let be a symmetric positive definite matrix, the Cholesky decomponsition expand on the LU decomposition and breaks down , where is a unique upper triangular matrix with positive diagonal entries. Cholesky decomposition can be used to generate correltaed random variables in Monte Carlo simulation
Matrix Interpretation
Consider a matrix:
To find the first principal component , we define it as the normalized linear combination of that has the largest variance, where its loading are normalized:
Or equivalently, for each score:
In matrix form:
Finally, the first principal component loading vector solves the optimization problem that maximize the sample variance of the scores . An objective function can be formulated as follow and solved via an eigen decomposition:
To find the second principal component loading , use the same objective function with replacement and include an additional constraint that is orthogonal to .
Geometric Interpretation
The loading matrix defines a linear transformation that projects the data from the feature space into a subspace , in which the data has the most variance. The result of the projection is the factor matrix , also known as the principal components.
In other words, the principal components vectors forms a low-dimensional linear subspace that are the closest (shortest average squared Euclidean distance) to the observations.
Eigen Decomposition
Given data matrix , the objective of PCA is to find a lower dimension representation factor matrix , from which a matrix can be constructed where distance between the covariance matrices and are minimized.
The covariance matrix of is a symmetric positive semi-definite matrix, therefore we have the following decomposition where ‘s’ are eigenvectors of and ‘s are the eigenvalues. Note that can be a zero vector if the columns of are linearly dependent.
If we ignore the constant , and define the loading matrix and factor matrix where . Then:
Now comes the PCA idea: Let’s rank the ‘s in descending order, pick such that:
Now we observe that the matrix is also a positive semi-definite matrix. Following similar decomposition, we obtain a matrix and matrix , where:
Here we have it, a dimension-reduced factor matrix , where its projection back to space, , has similar covariance as the original dataset .
Practical Considerations
PCA excels at identifying latent variables from the measurable variables. PCA can only be applied to numeric data, while categorical variables need to be binarized beforehand.
Centering: yes.Scaling:- if the range and scale of the variables are different,
correlation matrixis typically used to perform PCA, i.e. each variables are scaled to have standard deviation of - otherwise if the variables are in the same units of measure, using the
covariance matrix(not standardizing) the variables could reveal interesting properties of the data
- if the range and scale of the variables are different,
Uniqueness: each loading vector is unique up to a sign flip, as the it can take on opposite direction in the same subspace. Same applies to the score vector , asPropotional of Variance Explained: we can compute the total variance in a data set in the first formula below. The variance explained by the -th principal component is: . Therefore, the second formula can be computed for the :
A Side Note on Hypothesis Test and Confidence Interval ↺
A formal statistical data analysis includes:
hypothesis testings: seeing whether a structure is presentconfidence interval: setting error limits on estimates- prediction interval: setting error limits on future outcomes
We will discuss a typical setting as follow:
- Let be the
unknown parameter, and is the parameter estimator based on observations - Let be the estimator of , equal to
- In rare circumstances where is independent of the unknown , such as in regression settings where the error terms are i.i.d. normally distributed, we can show that it follows a t-distribution with degree of freedom.
- However, asymptotically as , the
Central Limit Theoremapplies which release us from the assumption restriction above. Under a variety of regular conditions:
- The
confidence intervalcan then be computed as:
The
hypothesis testof would:- accept that if
- reject that if
The
p-valueis such that the hypothesis test is indifference between accept or reject.In practice, t-distribution is typically used for regression data as it is more conservative (). For non-regression data, normal distribution is often used.
Some background on LLN and CLT:
Given i.i.d. random variable . Let
The
Law of Large Numbersstates that if , then a.s.The
Central Limit Theoremstates that if , then
- Therefore, if we have a consistent estimator for , meaning as ,
Slutsky's Theoremconcludes that
- We can then use the normal distribution to set confidence intervals and perform hypothesis tests.
Reference:
- An Introduction to Statistical Learning with Applications in R, James, Witten, Hastie and Tibshirani
- FINM 33601 Lecture Note, Y. Balasanov, University of Chicago